.png)



《乌鸦渐进矩阵》是最广泛使用的智商测试之一。我们将探讨存在的三种不同类型,它们的历史和改进,举一些问题示例,最后讨论它们的优缺点。在不到十分钟的时间里,您将对这种测试类型的特征有一个很好的了解。
拉文测试简介
尽管通常被理解为一个单一的测试,Raven矩阵实际上是三个不同的测试,具有相同类型的问题。第一个是彩色渐进矩阵(CPM),适用于五到十一岁的儿童。第二个是标准渐进矩阵(SPM),适用于十一岁到成年结束。第三个是高级渐进矩阵(APM),顾名思义,具有更高级和复杂的矩阵,旨在针对被认为高度智能的人。
所有测试由一组问题组成。在每个问题中,您会看到一个矩阵,其中的元素遵循一个或多个模式。矩阵的一个部分缺失,需要通过选择提供的选项来填补——其中只有一个是最合适的。
例如,APM有36道矩阵题,每道题提供八个选项。通常时间限制为40分钟,但也有不限制时间的版本。前者更多地测量能力范围(不限制时间),而后者则侧重于智力表现和效率(限制时间)。
随着每个新问题的出现,难度逐渐增加,要求“更复杂的推理类型”,直到个人达到一个阈值,此时任何新矩阵都变得太难以解决。
尽管CPM是儿童的彩色版本,但实际上,颜色并没有任何重要性,因为它们并不能帮助解决问题,使用它们的唯一目的是在完成任务时保持高昂的动力。这些基于颜色的测试也用于老年人和有障碍的人。
矩阵智商测试的诞生
在1938年,心理学家J. Raven创建了测试的第一个版本,即标准版本。作为一名年轻的心理学家,他在寻找智力基因的过程中帮助了他的导师Penrose教授。当时现有测试的复杂性使得研究变得困难,这促使Raven发明了新的测试,作为快速、简单且经济有效的智力评估方法。
儿童版(CPM)和高智商人士版(APM)都是在之后开发的,并于1947年出版。同年,测试题目从48道减少到36道,因为发现许多问题并未帮助区分智商。后来,出现了几次修订,提高了有效性并发布了新问题。
在拉文看来,这些测试旨在衡量“形成比较的能力、通过类比推理的能力,以及发展逻辑思维的方法,无论之前获得的信息如何”。正如我们在其他测试创作者如卡特尔身上看到的,拉文也试图创建一个不受教育和文化影响的测试。
然而,我们可能会被诱惑用当前的知识重新解读过去,因为实际上他从未认为测试测量的是一般智力,而是每个问题测试的是特定的思维系统。
在他的定义中,智力是指在任何情况下具备(i)必要的信息回忆能力和(ii)进行比较和类比推理的能力。因此,我们可以说拉文认为智力由两个组成部分构成。这就是为什么他在使用矩阵测试的同时,还采用了米尔希尔词汇测试来衡量智力。后来,全球智力结果与矩阵测试之间的高度相关性支持了仅使用其中一个测试作为足够好的预测。
矩阵问题
每个问题总是一个3x3矩阵矩形,包含九个单元格(有时为2x2以便于版本)。每个单元格中有一个或多个项目(如圆形、三角形、箭头等),右下角的单元格是空的。要填充空单元格,参与者必须从八个可能的答案中选择。
通过每个单元内不同项目之间以及与其他单元项目之间的关系,个人必须推断出存在哪些规则和关系,因此哪个答案最适合填充矩阵。正确答案是唯一的,因为总是只有一个明确的关系(或关系组)导致唯一的可能答案。
让我们先看两个基本示例,然后再深入探讨所需的最常见推理类型。现在是第一个矩阵:
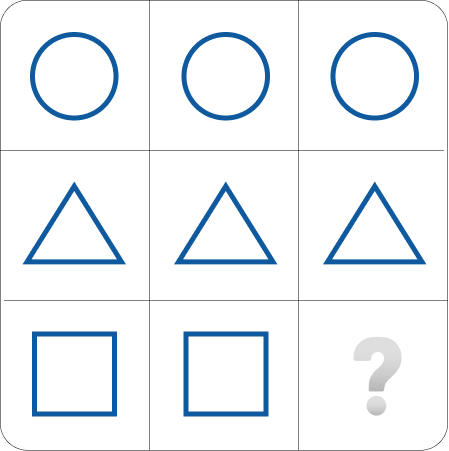
如我们所见,每一行都有相同类型的元素。第一行全是圆形,第二行全是三角形,最后一行有两个矩形。可供选择的响应选项是
.png)
所需推理:因此,最后一个空单元格必须与该行中的其他两个单元格相同类型,即没有任何颜色的矩形。这使得A成为唯一的可能选项。选择B将是一个错误,因为没有其他图形填充了颜色。下面您可以看到正确答案的完整矩阵结果。完整矩阵将是:
.png)
现在让我们来看第二个例子,稍微复杂一些。

这次我们可以看到,每一行都有相同类型的元素。而且,随着每一列向右移动,图形内部的颜色变得更加丰富。
我们必须选择的替代方案如下:
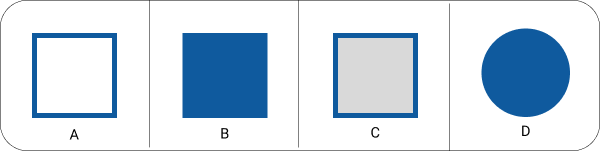
所需推理:因此,矩阵似乎结合了两个规则。一个是每行保持相同类型的图形。第二个是每列中图形内部的遮蔽程度,向右逐渐增加。这意味着我们应该选择B,因为它是与行中的图形相同的矩形,但也比其他两个更暗,后者在左侧列中已经出现,填充较浅。让我们看看答案:
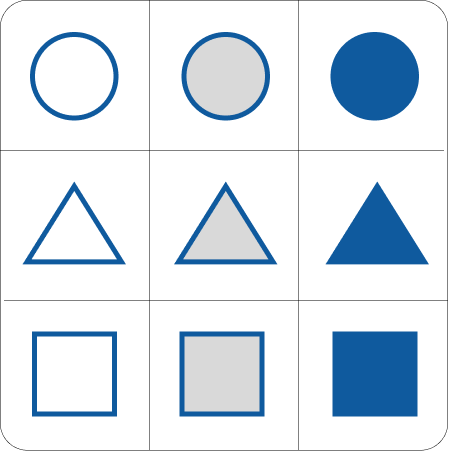
所需的推理类型
正如我们所说,从抽象层面来看,该测试衡量进行演绎和归纳推理的能力。一些必要的推理具体例子包括:
- 区分图形中的相似性和差异,并理解它们如何影响每个单元。
- 评估图形在感知领域中的方向,与自身及其他图形的关系
- 感知图形如何形成一个整体
- 分析图形的各个部分,并区分每种情况下重要的元素。
- 比较矩阵中每个部分的模拟变化
我们不能揭示测试使用的太多具体模式和规则,以免损害其完整性。但我们可以提到一些在问题中经常出现的基本规则作为例子:
- 连贯性:儿童提问的典型特征,故事只有在一个元素的情况下才能成立。
- 相同组件:当一个组件应保持与我们上面看到的示例相同。
- 连续模式:参与者需要找出列或行遵循的模式(例如,每列中的图形向右旋转等)。
- 数学运算的应用:就像每一列的元素数量是双倍一样。
- 关系与组合:例如,当不同单元的元素结合形成更复杂的项目时。
通常情况下,给出的问题解决方案是正确的,但推理却存在缺陷。也许答案是对的,但很可能下一个问题不会正确解决。那么,现在既然提到了错误,做测试时最常见的错误是什么呢?两个常见错误是:
- 不完整的相关性:当一个人未能揭示矩阵中所有的规则和模式时。常见于复杂问题中。
- 思想的汇聚:当不相关的细节本应被忽略却没有被忽略时。例如,在只有两个元素受到影响时,使用了一个尺寸模式,而这个模式本应被忽视。
它们应该在什么时候使用?
乌鸦测试用于教育、实验和临床环境。然而,它们的使用应限于不需要高精度的决策或情境,并且需要简单且经济有效的测试。例如,当研究的主要目标不是确切的智商时,这种测试在心理学研究中相当普遍。但它不用于重要决策可能影响个人生活的广泛临床评估。
根据年龄,您应该使用儿童版(CPM)或成人版(SPM或APM)。在教育环境中,通常会使用它来对儿童的智力进行基本预测。例如,高级矩阵版(APM)在高等教育中也被广泛使用。
有效性和可靠性
那么,这个测试可靠吗?测试的两个重要方面是它是否有效和可靠。可靠性指的是测试是否存在测量误差,换句话说,“如果你再做一次测试,结果会一样吗?”有效性则告诉我们是否真的在测量智力。测试结果是否与良好的学业表现相关?更好的测试结果是否意味着更有可能获得成功的职业?
在这方面,乌鸦测试的可靠性相当不错,在80%到90%之间,因此测量误差较小。至于有效性,确定测试是否有效的一个常见方法是将其结果与更成熟的测试进行比较。与更强大的韦氏量表相比,相关性实际上相当不错,约为55%到70%。但如前所述,这并不足以将这些测试用于任何目的。
缩写版本
由于测试需要40分钟,这在某些情况下可能太长,因此专家们创建了几种缩短版,时间更短,因此更快完成。
其中一种方法(Arthur和Day,1994)是创建一个仅由12个问题组成的测试,时间为12分钟(而不是36分钟,因此是原测试的33%),只选择那些存在真正难度跃升的问题。
然而,一些心理学家批评这种方法,因为解决更难的问题通常依赖于解决之前问题中的简单模式。因此,出现了一个新版本,参与者在20分钟的时间限制内完成原始问题集,并采用不同的评分标准。
两种选择 在预测智商方面表现良好——当然不如原版那么好——
优点和缺点
它的优点在于交付非常简单,且速度相当快。这使得可以在没有大量和高成本投入的情况下测试大群体,这正是Raven最初创建它的原因。此外,由于测试几乎没有指示且完全非语言化,它允许在不同背景和教育水平的人之间进行比较,而不受偏见影响。
从负面来看,最大的弱点是它专注于流体智力,而没有评估许多其他认知能力。确实,没有先前知识的推理和归纳是最具预测能力的,但这并不全面。这也解释了为什么韦氏量表在有效性上更胜一筹,并用于更准确的预测,因为它是一种更长且更全面的测试。
另一个弱点是,尽管测试是文化公正的,但各国之间的结果差异足够显著,值得建立地方标准进行比较。这使得文化公正假设部分受到质疑。似乎社会经济因素与更高的认知发展有某种关系,可能通过良好的营养和更好的健康来实现。此外,在城乡居民之间也存在一些差异,尤其是在非洲等国家,城乡差异巨大。
摘要
正如我们所见,乌鸦智商测试是任何智力测试者工具箱中的强大工具。它快速交付、成本低且易于管理。然而,它的使用仅限于需要大致预测的场景。由于它只测试一个智力因素——流体智力,尽管与智力高度相关,但它仍然是对一个人能力的相当有限的评估。



.png)



